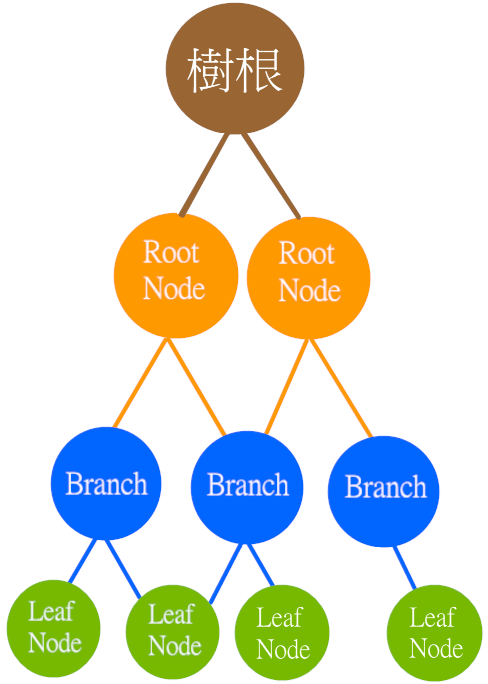
一種機器學習演算法,以樹狀結構表示一系列決策規則,每個節點代表一個決策,而葉節點則代表最終的預測結果
根節點(Root node) |
沒有父節點節點,通常為最開始的節點,代表一個特徵或屬性 |
|---|---|
內部節點(Internal node) 分支(Branch) |
有子節點節點,代表一個決策規則,根據節點的特徵值進行分裂 |
葉節點(Leaf node) |
沒有子節點的節點,代表一個類別標籤或連續值,即最終的預測結果 |
圖片來源:自己做的
過程是從根節點開始,對每個內部節點進行分枝,直到生成所有葉節點。分枝的過程是通過某種基準來評估每個特徵的分割效果,選擇能最大化訊息增益或其他指標的特徵進行分割
信息熵H(D) = -∑pi * log2pi
D |
樣本集合 |
|---|---|
pi |
屬於第i類樣本比例 |
信息增益Gain(D, A) = H(D) - ∑|Dv|/|D| * H(Dv)
A |
屬性 |
|---|---|
Dv |
根據屬性A劃分得到的子集 |
基尼指數Gini(D) = ∑pi * (1-pi)
增益率(Gain Ratio):考慮特徵值的個數,可以防止過度偏向取值較多的特徵Gini 指數(Gini Index):衡量資料的不純度,即資料中不同類別的比例分類問題:信用評估、疾病診斷、文本分類迴歸問題:房價預測、銷售額預測數據挖掘:關聯規則挖掘、異常檢測異常檢測:檢測欺詐交易、網路入侵等異常行為from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# 載入鳶尾花數據集
iris = load_iris()
X = iris.data
y = iris.target
# 分割訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_st
ate=0)
# 創建決策樹模型
clf = tree.DecisionTreeClassifier()
# 訓練模型
clf = clf.fit(X_train, y_train)
# 進行預測
y_pred = clf.predict(X_test)
# 評估模型
print("Accuracy:", clf.score(X_test, y_test))
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(12,8))
plot_tree(clf, filled=True)
plt.show()
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
# 載入鳶尾花資料集
iris = load_iris()
X = iris.data
y = iris.target
# 分割訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 建立決策樹分類器
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
# 繪製決策樹
plt.figure(figsize=(12,8))
plot_tree(clf, filled=True)
plt.show()
決策樹是一種簡單易懂且應用廣泛的機器學習算法。它在處理分類和迴歸問題時具有獨特的優勢。然而,決策樹也存在過擬合等問題,需要通過剪枝等方法來改善。在實際應用中,可以結合其他算法,例如:隨機森林、梯度提升樹來提高模型的性能


 iThome鐵人賽
iThome鐵人賽